| Version 3 (modified by bartek, 13 years ago) (diff) |
|---|
End-user Information
The main goal of the QosCosGrid middleware was a construction of a flexible, efficient and secure distributed IT system being able to deal with large-scale simulations onto distributed computing resources connected over local and wide area networks, in particular using Internet connections. From the development perspective, QosCosGrid supports three classes of use cases covering a wide-range of possible applications, namely: Java use cases taking the advantage of ProActive library as the parallelization technology, ANSI C or similar applications, which rely on the Message Passing Paradigm, and multi-scale applications based on Muscle library.
QCG OpenMPI
The Message Passing Interface (MPI) is de facto a standard in the domain of parallel applications demanding computational resources that are beyond what single machine can provide. It delivers end-users both the programming interface consisting of simple communication primitives and the environment for spawning and monitoring MPI processes. A variety of implementations of the MPI standard is available (both as commercial and open source). In QosCosGrid, it was decided to use OpenMPI implementation of the MPI 2.0 standard as input for further enhancements. Of key importance were the inter-cluster communication techniques that deal with firewalls and Network Address Translation. In addition, the mechanism for spawning new processes in OpenMPI needed to be integrated with QosCosGrid?-developed middleware. The extended version of the OpenMPI framework was named QCG-OMPI (where QCG stands for QosCosGrid). The extensions were three-fold: 1 - internally, QCG-OMPI improves the MPI library by featuring multiple connectivity techniques to enable, when possible, direct connections between MPI ranks that are located in remote clusters potentially separated by firewalls; 2 - the MPI standard was extended to comply with the QosCosGrid semi-opportunistic approach, by providing a new interface to describe the actual topology provided by the meta-scheduler; and 3 - many MPI collective operations were upgraded to be hierarchy-aware, and optimized for the Grid.
Attachments
-
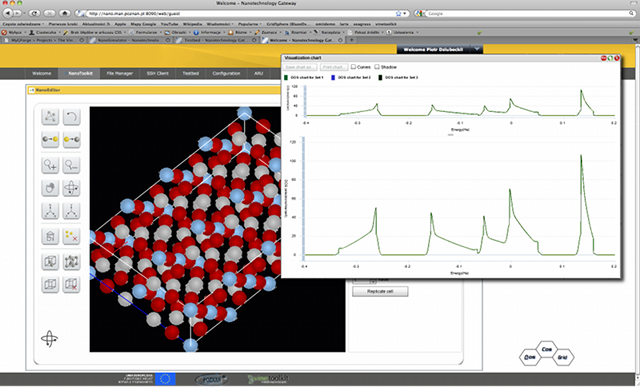
QCG-ScienceGateway.png
 (201.5 KB) -
added by bartek 13 years ago.
(201.5 KB) -
added by bartek 13 years ago.
-
QCG-Icon.png
(196.2 KB) -
added by mmamonski 13 years ago.
-
qcg-mobile.png
(178.0 KB) -
added by piontek 13 years ago.
QCG Mobile
-
qcg_client.png
(126.0 KB) -
added by piontek 11 years ago.
{kind=link}
{kind=link}
{kind=link}
{kind=link}